Es waren sechs Minuten in einem Vortrag von Mikko Hypponen auf der re:publica 2015, die mich erstmals verstehen ließen, wie ernst die Lage ist. Natürlich gab es bis dahin im Freundeskreis schon häufig Diskussionen darüber, was Google, Facebook, Twitter und Co über den Einzelnen wissen. Die Vorstellung beschränkte sich damals darauf, dass diese vielgescholtenen Datenkraken alles wissen, was ihre Nutzer in ihren Diensten und Plattformen tagtäglich tun, schreiben, klicken und teilen. Das war und ist schon bedenklich genug, doch offensichtlich nur die Spitze des Eisberges.
Besagter Vortrag ermutigte, doch einmal die Seiten zu wechseln und die Perspektive der Werbetreibenden einzunehmen. Die Perspektive derer, die uns mit möglichst zielgerichteter Werbung zum Konsum verführen wollen. Wie das geht? Ganz einfach. Hier ein Selbstversuch mit Twitter – bei Facebook und Google ist der Ablauf nahezu identisch.
Hinter dem Vorhang von Targeting
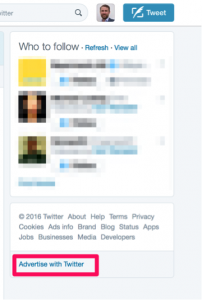
Um in die große weite Welt der Social-Media-Werbung einzutreten, logge ich mich im Browser bei Twitter mit meinem kleinen, privaten Account ein. Ein kleiner Link in der rechten Leiste (war der schon immer da?) zeigt den Weg zum „Advertising“ – in der deutschen Version heißt es erwartungsgemäß “Werbung”. Platziert ist der unauffällige Link bei all den anderen Dingen, die ein argloser Nutzer der Plattform möglichst übersehen soll: Geschäftsbedingungen, Datenschutzeinstellungen und Opt-out-Optionen für Werbung. Man will ja schließlich keine schlafenden Hunde wecken.
Der Link führt mich direkt in die „Ad-Management-Plattform“. Ich komme mir ein bisschen vor wie ein Kind, das zum ersten Mal hinter die Kulisse einer großen Bühne sieht.
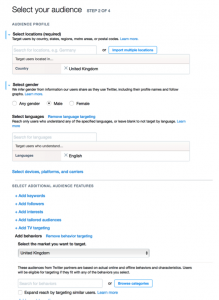
Einmal drin, soll ich als erstes mein Ziel definieren: Ob ich durch meine Anzeigen Klicks, Likes, Follower, Retweets oder irgendetwas anderes generieren möchte? Follower sollen es sein. Noch ein Klick und ich habe eine „Kampagne“ angelegt, der ich nun einen Namen geben soll. Der Anschaulichkeit halber entschließe ich mich für “Creepy targeted advertising”. Auch wie lange meine Kampagne laufen soll, kann ich festlegen. Aber vor allem kann ich mir hier sehr genau aussuchen, welche Nutzer meine Anzeige sehen sollen. Das ist das sogenannte Ad-Targeting, mit dem Plattformen wie Facebook, Twitter und Google aber auch deutsche Anbieter wie United Internet Media werben.
Fadenkreuz auf dem Rücken
Natürlich kann ich meine Zielgruppe nach grundlegenden Attributen auswählen, die ein anmeldepflichtiger Dienst wie Twitter naturgemäß über seine Nutzer weiß: Geschlecht, Sprache, Heimatland etc. Ich wähle alle englischsprachigen Männer im Vereinigten Königreich (warum ausgerechnet UK, dazu später mehr). Soweit so gut.
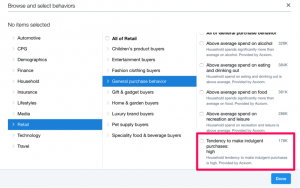
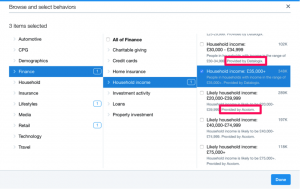
Wenige Zeilen weiter habe ich dann aber auch noch die Möglichkeit, meine Zielgruppe nach “behaviors”, also Verhaltensmustern einzugrenzen. Hier wird es interessant. Denn ich brauche nur zwei Klicks und sehe mich einem umfassenden Katalog an Zielgruppenkriterien gegenüber. Der erlaubt mir beispielsweise, all jene auszuwählen, die auf ein Haushaltseinkommen von über 35.000 Pfund zurückgreifen können, sich für Mode interessieren, Luxusmarken bevorzugen und zu überschwänglichem Konsum neigen. Ich bekomme dazu auch gleich die Info, auf wie viele Zwitscherer im gewählten Land die jeweilige Beschreibung passt. Ganze 116.000 Twitter-Nutzer mit Hang zum Luxus gibt es wohl im Vereinigten Königreich.
Das alles ist natürlich super, wenn ich beispielsweise Designer-Handtaschen verkaufen will. Denn so schaffe ich es, jedem Luxusliebhaber – und eben nur diesen – virtuell mein Louis Vuitton Plakat direkt ins Wohnzimmer zu hängen. Ohne Streuverluste und für den Nutzer höchstrelevant.
Doch als Nutzer stellen sich einige Fragen: Woher kennt Twitter mein Haushaltseinkommen? Wieso wissen sie, was für Marken ich kaufe? Oder, wenn ich mehr als der Durchschnitt für Alkohol ausgebe, nachsichtig beim Geldausgeben bin, oder lieber Chips statt Schokolade kaufe? Auf all diese Attribute und viele mehr lässt Twitter ein Targeting zu. Unmöglich kommen diese Informationen aus den Tweets, die bekanntlich mitgelesen werden. Ich jedenfalls habe noch niemanden sein Einkommen tweeten sehen. Woher zum Teufel wissen die das alles?
Der große Handel der Datenbroker im Hintergrund
Wie ich in besagtem Vortrag auf der re:publica erfahren konnte, liegt der Schlüssel zur Antwort in kleinen Zusätzen im Targeting-Tool von Twitter. Dort steht beispielsweise bei den Einträgen zum Haushaltseinkommen: “Provided by Datalogix”. An anderer Stelle ist auch mal “Acxiom” als Datenlieferant erwähnt. Nie gehört? Keine Angst, das geht fast jedem so. Denn die Öffentlichkeit stürzt sich bei Datenschutzthemen zwar immer gerne auf die großen Namen, doch der Großteil der Akteure im Geschäft mit den Daten operiert unerkannt im Hintergrund.
Das sind sogenannte Datenbroker (oder Information Broker). Sie helfen werbefinanzierten Diensten wie Facebook, Twitter oder Google dabei, die Profile ihrer Nutzer um Daten zu erweitern, die sie selber nicht erheben können.
 Datenbroker sammeln alle möglichen frei verfügbaren Daten aus Netz, öffentlichen Auskunftsstellen und Registern. Zusätzlich werden Daten von extern eingekauft, beispielsweise von Trackingprovidern oder Treueprogrammen wie Payback (kaum jemand hat umfassendere Daten über das Online- und Offline-Kaufverhalten). Auch Anbieter von Apps, die das Verhalten ihrer Nutzer aufzeichnen, finden in Datenbrokern dankbare Kunden. Die Liste der Unternehmen die untereinander Daten austauschen und verkaufen ist lang – wie ein Blick auf die Partnerunternehmen von Acxiom erahnen lässt.
Datenbroker sammeln alle möglichen frei verfügbaren Daten aus Netz, öffentlichen Auskunftsstellen und Registern. Zusätzlich werden Daten von extern eingekauft, beispielsweise von Trackingprovidern oder Treueprogrammen wie Payback (kaum jemand hat umfassendere Daten über das Online- und Offline-Kaufverhalten). Auch Anbieter von Apps, die das Verhalten ihrer Nutzer aufzeichnen, finden in Datenbrokern dankbare Kunden. Die Liste der Unternehmen die untereinander Daten austauschen und verkaufen ist lang – wie ein Blick auf die Partnerunternehmen von Acxiom erahnen lässt.
Daten werden mit Profilen verknüpft
Als nächstes führen die Datenhändler die verschiedenen Datenquellen über sogenannte „Unique Identifier“ wie Telefonnummern oder E-Mail-Adressen zu umfassenden Profilen zusammen, die sie dann gewinnbringend an Twitter, Facebook, Google und andere Werbeplattformen weiterverkaufen können. Diese wiederum können die Informationen mit ihren ganz individuellen Nutzerprofilen verknüpfen. Am Ende kann Facebook dem arglosen Max Mustermann nicht nur ganz gezielt die „Kelloggs Smacks“ Werbung auf den Bildschirm schicken, sondern Kelloggs dann auch die Rückmeldung geben, ob der Max anschließend auch brav gekauft hat.
Weil dieser geschlossene Kreis von Ad-Targeting und Erfolgsmessung für jeden Werbetreibenden einen enormen Wert darstellt, stehen Datenbroker hoch im Kurs. Datalogix hat bereits 2014 Investorengelder in Höhe von 45 Mio. USD eingesammelt, um den Datenaustausch mit Twitter und Facebook in Gang zu bringen und wurde noch im selben Jahr von Oracle gekauft. Zu diesem Zeitpunkt analysierte Datalogix jedes Jahr Verbraucherausgaben in Höhe von 2 Billionen (!) USD. Acxiom brüstete sich schon ein Jahr zuvor damit, Daten über mehr als 300 Millionen Amerikaner und auch mehr als 44 Millionen Deutsche zu führen – im Schnitt über 1.500 Datenpunkte pro Person. Wie viele Datensätze es heute, zwei Jahre später, sind, lässt sich nicht so einfach herausfinden. Man gibt sich bedeckt, was das angeht – wahrscheinlich will man niemandem Angst einflößen oder die Regulatoren auf den Plan rufen.
Ungewollte Kunden werden ausgeschlossen
Wie angedeutet habe ich in meinem kleinen Selbstversuch ganz bewusst das Vereinigte Königreich als Kampagnen-Ziel ausgewählt. Und zwar aus dem Grund, dass Twitter das Behavior Targeting derzeit „nur“ in UK und USA anbietet. Die Targeting-Möglichkeiten in den USA sind übrigens noch umfassender als in UK. So steht beispielsweise auch die Kreditwürdigkeit als Targeting-Option zur Auswahl. Bei Facebook auch die sogenannte „ethnische Affinität“, ein prominentes Beispiel für die Schattenseite des Targeting. Denn so kann ich als Werbetreibender nicht nur meine gewollten Kunden ganz gezielt ansprechen, sondern eben auch ungewollte Kunden ganz gezielt ausgrenzen. Beispielsweise, indem ich eine Immobilienanzeige den Wohnungssuchenden mit einer Affinität zu Afro-Amerikanern vorenthalte.
Während in den USA schon über solche Details diskutiert wird, wähnt man sich hierzulande meist in Sicherheit. Doch wie sieht es in Deutschland tatsächlich aus? Was macht Acxiom mit den mittlerweile mehr als 44 Millionen Profilen von Deutschen? Oder vorher noch: Was darf ein Unternehmen mit diesen Daten machen? Gute Frage – leider ohne eindeutige Antwort. Denn Gesetze bieten nur bedingt Schutz, wenn niemand im Blick hat, welche Datenströme existieren, wo sie hinfließen und was sie beinhalten, wie der NDR erst kürzlich aufdecken konnte.
Augenmaß bei der Herausgabe von Daten
Am Ende stehen, wie leider oft, sehr viele Fragezeichen. Die Gesetzgebung ist undurchsichtig und voller Grauzonen, die Profiteure im Datenmarkt geben sich bedeckt, und die Möglichkeiten der Selbstauskunft sind begrenzt und bieten kaum Einflussnahme. Sollte in meinem ganz persönlichen Datensatz beispielsweise etwas von einer Affinität zu Extremsportarten stehen, etwa, weil mein Sohn gerne die letzten YouTube-Videos und Neuerungen im Base-Jumping auf meinem Rechner ansieht, dann erfahre ich das womöglich nie. Und selbst wenn, kann ich es nicht korrigieren. In der Anschaffung einer Lebensversicherung kann mir so ein Stigma dann in der Zukunft durchaus im Weg stehen. Oder meinem Sohn.
So ist das Einzige, was bleibt, die Datensparsamkeit. Im Zuge der NDR-Recherchen hat mobilsicher.de einen umfassenden Leitfaden zusammengestellt, der Tipps gibt, wie man sich auf Smartphone und Laptop vor den Datensammlern schützen kann. Doch das Prinzip der Datensparsamkeit gilt auch abseits der Bits und Bytes. So sollte man sich vor Anschaffung der 30sten Bonuskarte überlegen, ob vielleicht nicht nur ein Treueprogramm, sondern auch ein Datengeschäft dahintersteht. Auch so manche Online-Umfrage ist am Ende alles andere als anonym.
Grundsätzlich gilt: Immer erst kritisch das Motiv hinterfragen, bevor man bereitwillig seine Informationen preisgibt. Und davor noch: Sich ein wenig schlau machen und zumindest versuchen zu verstehen, was hinter dem Vorhang der kostenlosen Dienste und Rabatte so alles vor sich geht. Wer aufmerksam bis hierher gelesen hat, ist hoffentlich schon einmal ein Stück schlauer – und vorsichtiger.
Mein eigenes digitales Profil ist mittlerweile definitiv falsch. Ob ich als potentieller Base-Jumper eingestuft werde, kann ich leider nicht sagen. Doch ganz offensichtlich als jemand, der willig ist, Werbung auf Twitter zu schalten. Diesen Schluss erlauben mir Twitters freundliche Erinnerungen, doch endlich meine Kampagne live zu schalten.
Fabio Marti
Über den Gastautor: Fabio Marti studierte Englische Sprachwissenschaften, Psychologie und Soziologie an der LMU München. Seit seinem Master-Abschluss im Jahr 2004 ist er fest in der IT-Branche verankert und sammelte zuletzt neun Jahre Erfahrung bei einem Anbieter von IT-Sicherheitslösungen. Seit 2016 verantwortet er das B2B Geschäft bei der Brabbler AG, einem Startup, welches sich der Wiederherstellung von Vertraulichkeit und Privatsphäre in der digitalen Welt verschrieben hat.
Fabio Martis linkedin-Kontakt